
PARTNER CONTENT
AI has overtaken talent as hedge funds’ top priority. Now what?
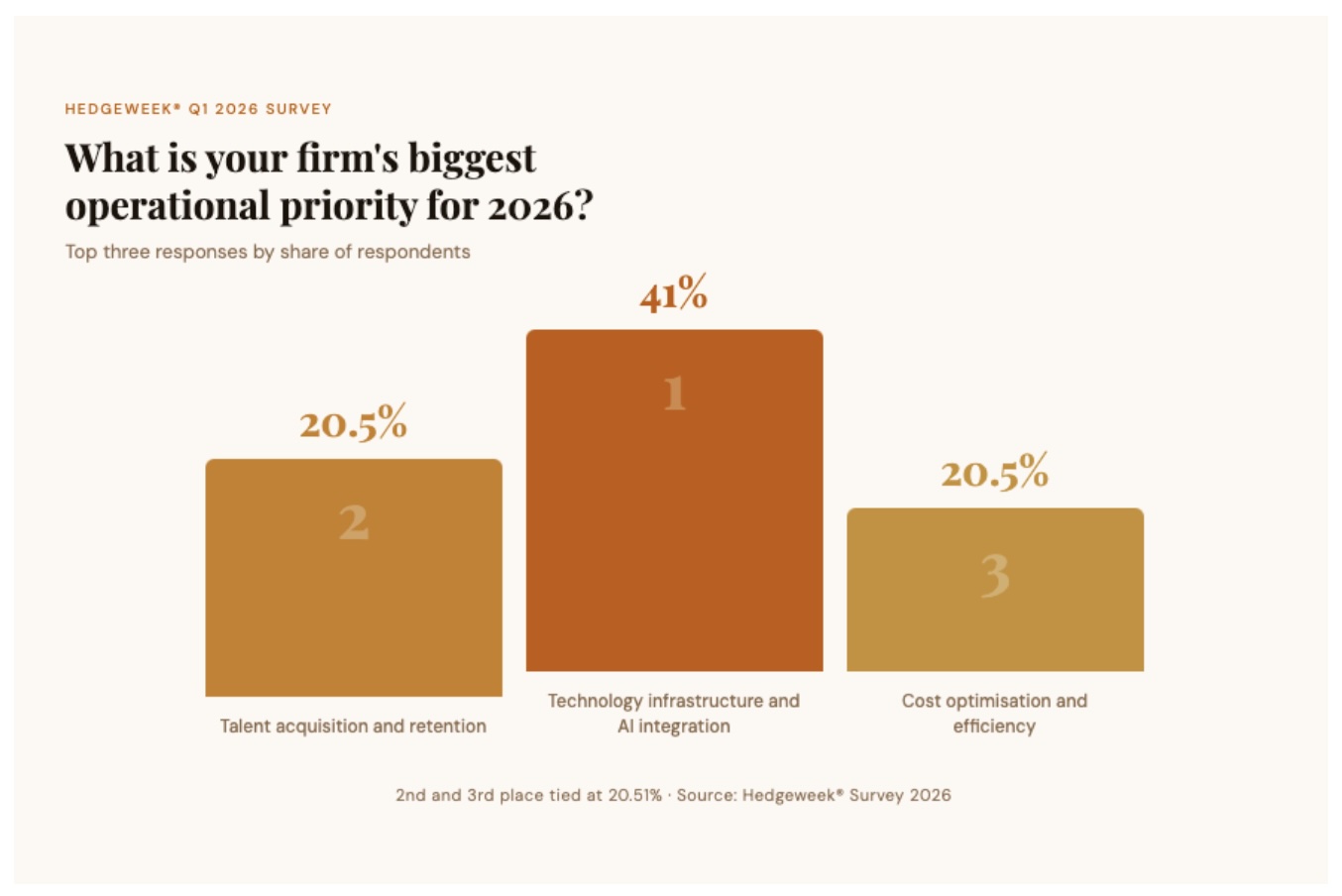
Something shifted in the hedge fund industry’s collective mindset over the past 12 months. According to the Hedgeweek® Q1 2026 Global Outlook Survey of more than 100 hedge fund managers, 41% now rank AI integration into their investment processes as their biggest priority for the year — ahead of both cost optimisation and talent acquisition and retention, the two issues that have traditionally dominated the conversation.
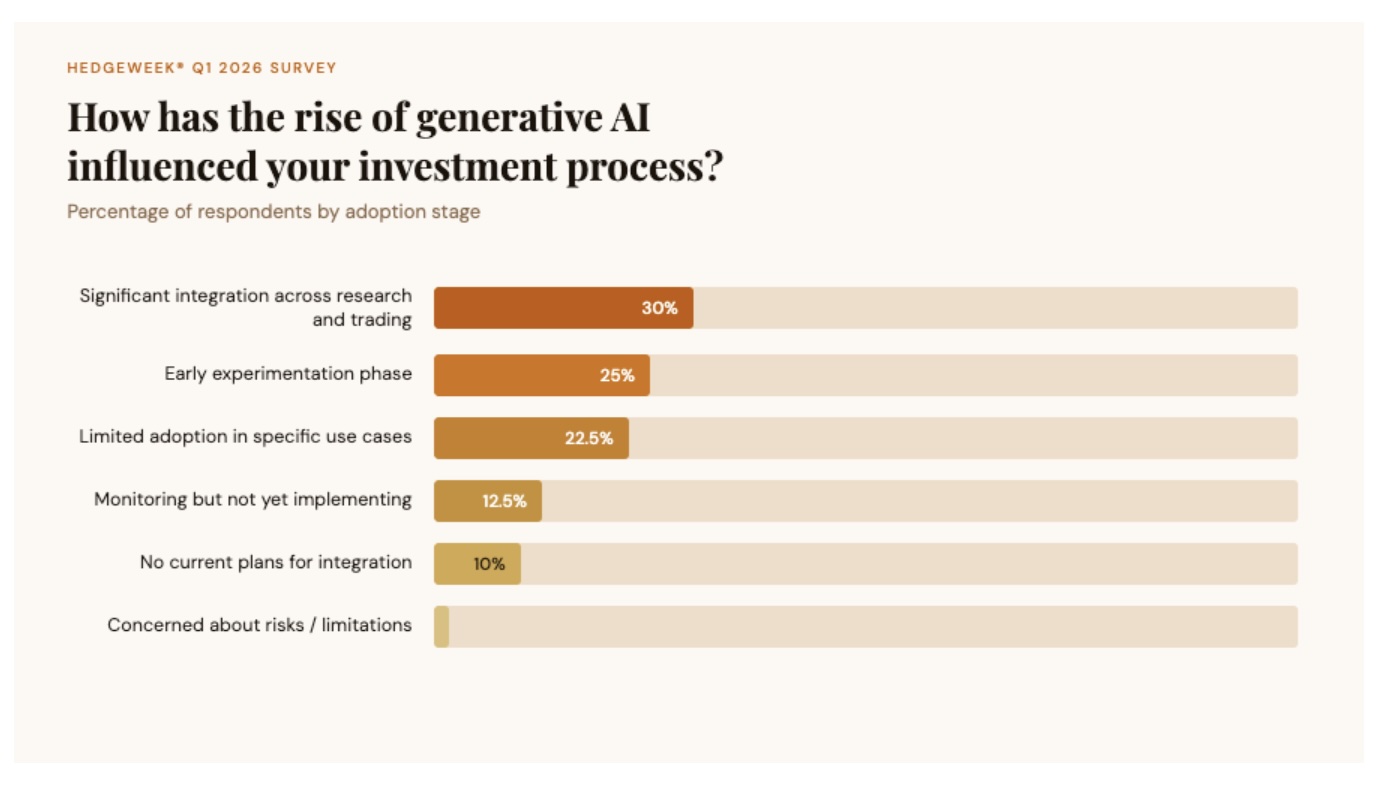
The shift is not merely rhetorical. Nearly a third of surveyed managers report significant AI integration across their research and trading processes, while a further quarter are actively experimenting. Not a single respondent expressed concern about the risks or limitations of generative AI.
That last data point is perhaps the most revealing. The industry is not debating whether it should adopt AI. It is debating how best to do it. And according to the people building the infrastructure that hedge funds rely on, the answer to that question begins not with models, algorithms, or agents — but with data.
“You can’t put a layer of AI on your workflows, no matter how good of a tool it is, if you have disorganised or inconsistent data and expect institutional-grade insights,” says Dean Schaffer, CEO of Lightkeeper, a Boston-based data analytics firm that has spent 15 years managing portfolio data for hedge funds across all investment strategies and asset managers. “AI is only as good as the data you put into it.”
The trust gap: why AI in hedge funds is harder than it looks
The promise of large language models in investment management is seductive in its simplicity: ask a question in plain English, receive an answer in seconds. But beneath that simplicity lies a problem that most general-purpose AI tools are not designed to solve.
LLMs like Claude and ChatGPT are exceptional at processing and reasoning over unstructured, publicly available information – market commentary, earnings transcripts, macroeconomic analysis. But the questions that matter most to a portfolio manager on any given morning tend to be about their own book: their positions, their attribution, their risk exposures, their analysts’ track records. That is proprietary data, and it lives behind walls that general-purpose AI cannot reach.
“There are two kinds of data that come through LLMs,” Schaffer explains. “Deterministic and non-deterministic. Non-deterministic data – it’s okay if it’s generally accurate. Deterministic data, you can’t be off on your own proprietary data.”
This distinction is at the heart of what might be called the industry’s “trust gap”. Hedge funds are confident that AI will transform their operations. Hedgeweek® data confirms this emphatically. But most firms lack the underlying data architecture to use AI with the precision and auditability their investment processes demand.
Danny Dias, Lightkeeper’s chief product officer and co-founder, puts it in terms that any technologist would recognise. “If you think about data organisation in the 2000s, everyone figured out the data warehouse. Then the question became, what interface do I put on this? That gave rise to solutions like Tableau, Power BI. The next phase now is that if you organise your data and provide the tools, you’re going to have a system that can generate insights at a pace that used to be massive human capital costs.”
The implication is that the real AI opportunity for hedge funds is not the model itself but the organised, validated data layer it reasons over. And for most firms, that layer either doesn’t exist or is fragmented across spreadsheets, accounting systems, and siloed internal tools.
The hallucination problem – and why “the AI told me” is a career risk
For all their sophistication, LLMs have a well-documented tendency to sound authoritative even when they are wrong. In consumer applications, this is an inconvenience. In institutional investment management, it is a material and career risk.
Dias frames the problem in terms of system design. “One of the challenges was always: you have all these great tools, how do you expose them in a UI? Natural language is actually a much better browsing mechanism. But if the other side is less granular than the browsing mechanism, that’s where you get hallucinations – if I can’t calculate what your average position size was, the AI is going to give you a number, but it’s going to be dead wrong.”
This is a critical point for the industry to absorb. The hallucination risk in hedge fund AI is not primarily about the language model fabricating facts about the French Revolution. It is about the model returning a plausible but incorrect number for a client’s sector attribution or risk exposure. It can be a number that might then find its way into an investor letter, a risk report, or a trading decision.
When Lightkeeper convened a roundtable with clients early in its AI development process, the feedback was unequivocal. “You can’t have data in a black box, it has to be transparent and trusted,” Schaffer recalls. The response was to build an architecture in which every AI-generated answer links back to the underlying calculation in the Lightkeeper platform, allowing users to verify any output against the source.
“If you just built a SQL table and put an LLM interface on top and it gives you the number seven – how do I get back to that?” Dias asks. “You need to enable the user to go back and decompose the information. We truly believe that UIs are still going to be critical components of the AI ecosystem, because you need to get back to the original information to check it.”
Bridging the gap: how MCP is changing the architecture of AI in finance
Lightkeeper’s answer to the trust gap is Beacon, an MCP-based tool now available to all of its clients. MCP – Model Context Protocol – is an open standard that allows large language models to access data sources in a governed, secure manner. In practical terms, it means a Lightkeeper client can open Anthropic’s Claude or OpenAI’s ChatGPT, connect to Lightkeeper via MCP, and query their own portfolio data in natural language, with every answer traceable to validated source data.
The architecture is significant for several reasons. The calculations are performed by Lightkeeper’s engine – not by the LLM. The data remains ring-fenced within the client’s environment. And every result includes a link back to the platform for verification.
“When you type something into Claude or ChatGPT, if you’re a Lightkeeper client, it gives you the answer and then provides a link back to Lightkeeper so you can confirm and validate,” Schaffer says. “This is all deterministic data. It can’t be wrong. Our clients asked us to build it this way.”
There is also a cost dimension that is accelerating adoption. Dias notes that at the beginning of 2024, integrating MCP effectively required an LLM enterprise licence costing a minimum of $70,000 a year. By the end of that year, similar LLM capabilities were available on a teams programme for as little as $150 per month. “Much like video game consoles — once you cut the price, they go more mass market,” he says.
But while access to large language models is becoming cheaper, the underlying data challenge remains. “The client’s data is not getting more mass market,” Dias observes. “They still have all the problems of: how do I actually organise my data?”
The death of the spreadsheet PM
For all the discussion of frontier AI models and agentic workflows, Lightkeeper’s most formidable competitor may be the most prosaic tool in finance: Microsoft Excel.
“Our number one competitor is Excel,” Dias says with a candour unusual in enterprise software. “We love Excel. But the problem is that Excel solves three different things for people: it’s your data storage layer, your computation layer, and your presentation layer. We love it as a presentation layer. But those other two become non-scalable.”
This is the unglamorous reality behind AI adoption in hedge funds. Before a firm can benefit from natural language queries over portfolio data, or automated analyst evaluation, or proactive risk alerts, it needs to have moved beyond a world in which critical investment data lives in bespoke spreadsheets maintained by a single person.
Platforms like Lightkeeper’s, built over years of servicing hundreds of clients, provide hundreds of pre-calculated statistics and hundreds of filters across portfolio data. In case of Lightkeeper, their tool can ingest data from more than 90 different sources and synchronises against official books and records rather than recomputing from scratch — a distinction Dias considers fundamental to data integrity.
“The most common approach when you look at risk systems is that they take a minimal amount of data from an accounting system and make projections from there,” he explains. “We are literally a transformation of the accounting books of records into what we call an investment book of records, by synchronising the data as it stands.”
From interactive to proactive: the agentic frontier
Both Schaffer and Dias are clear-eyed about where the technology is heading. The current phase – in which users ask questions and receive validated answers – is just the beginning.
“As you see those interactions, those questions, this is where agentic systems come in,” says Dias. “If I know you like looking at your portfolio this way, what if every time the numbers change, we start using that same view and proactively flag when the world has changed? The insights come to you automatically, rather than you having to ask. You’re going to see the transition from an interactive component with AI to a consumption-based model, where it starts pushing towards you.”
Lightkeeper is already moving in this direction with Lumina, its in-platform AI tool that surfaces insights proactively while users work within the system. Combined with Beacon’s external MCP-based querying, the firm is positioning itself as the connective tissue between institutional data and the rapidly evolving AI ecosystem.
The bottom line: start with your data, not your model
If there is a single lesson from Lightkeeper’s 15 years in hedge fund data analytics, it is that the firms best positioned to benefit from AI are the ones that invest in data infrastructure before AI becomes their top priority. The magic wand is not coming for firms that have not done the foundational work.
“I don’t know if you need to fix everything at once,” Dias counsels, “but you probably need to start thinking about how you organise the data sets that matter to you. Because without that organisation, it’s not coming — the words don’t distinguish themselves enough. You need to be very precise. You need to provide the AI with better data.”
Schaffer is equally direct. “When you’re able to show AI in action with verifiable results, with accurate data, and show the ability to uplift day-to-day work and create operational alpha – there is a light that goes off. The question is: what do you do about it?”
For an industry that has made AI its top priority, the answer cannot be to wait. But it also cannot be to rush headlong into tools built on unreliable foundations. The firms that win the AI race in hedge fund management will not be those with the flashiest models. They will be those that understood, early enough, that the real competitive advantage was always in the data.
 Dean Schaffer, CEO, Lightkeeper
Dean Schaffer, CEO, Lightkeeper








